Latest version: 4.3.x
Kafka Quotas and per tenant cost center charging
Question
How to allocate costs of my streaming data platform across different cost centers and tenants ie. product teams ?
Answer
This article highlights how Cost Center allocation (across one of more Apache Kafka clusters) can be
implemented using the Kafka Quotas capability. Consumption patterns will be used to identify how different
product teams consume platform resources in order for them to share the operational cost.
The two key technical elements, that the reader should be aware are:
- Kafka Quotas A native capability of Apache Kafka that can throttle network consumption resources
- Client-ID - An identifier of a Kafka consumer or Kafka producer that is optional and passed to a Kafka broker with every request, with the sole purpose of tracking the source of requests on a logical / application name for monitoring aggregation.
Multi-tenant example
For example, a Kafka cluster is shared across 3 different product teams (3 lines of business). The total available network
I/O is 20 MBytes/sec.
- Product team A requires guaranteed produce and consumer rates of
10MB/sec - Product team B requires guaranteed produce and consumer rates of
6MB/sec - Product team C requires guaranteed produce and consumer rates of
4MB/sec
Cost allocation for the above, should be 50% Team A, 30% Team B, 20% Team C.
How to implement Cost allocation
Example Quotas for a multi-tenant Kafka cluster with 3 main projects:
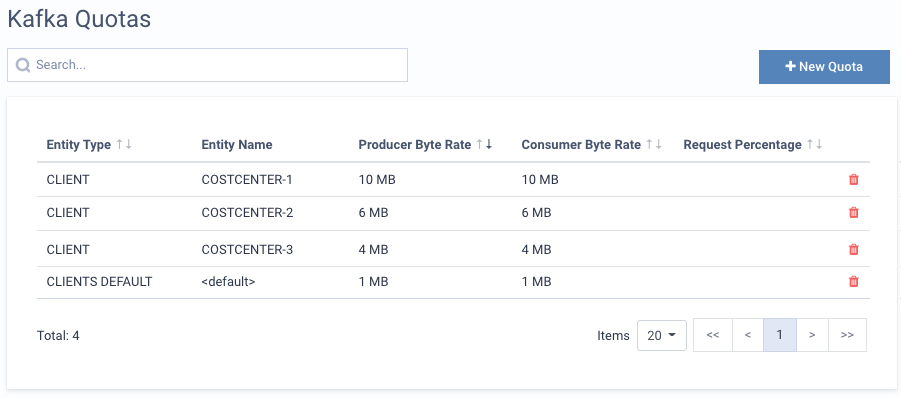
In the above screen we have implemented one Kafka Quota per cost center (or per project team). We are using the Client-ID as the main identifier, and have added the guaranteed consume and produce rates. (The request percentage quota has been intentionally omitted, as it will not add any additional value)
Note: In addition to the predefined quotas, we have added a threashold of 1MB/sec for CLIENTS DEFAULT.
It is highly recommended to over-allocate and provide a default value for any “unnamed” client. That will
allow developers to use their favorite tools for data productivity and observability such as
kafka-console-consumer, or Lenses and also any application (micro-service, machine learning, data pipeline)
can still operate in a “slow lane” until they have migrated and are properly annotating which project they belong to.
For the technical reader, keep in mind that Apache Kafka implements a specific set of Quota precedence rules.
For example a “named client” will always be allocated to the first matching /clients/<client-id> quota, and any
“unnamed client” will fallback to /clients/<default>.
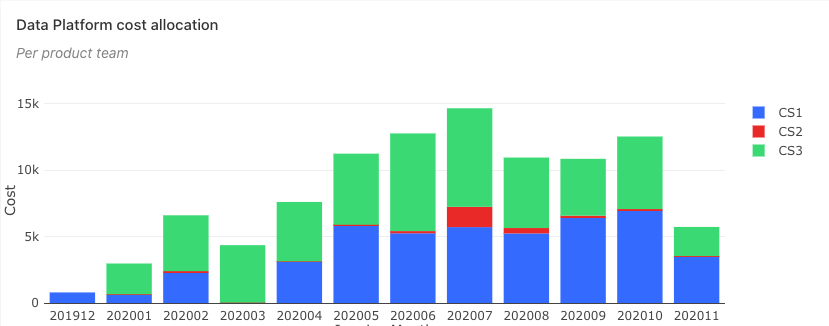
Cost allocation reporting
On a large scale organization having 10s of Kafka clusters, all the Kafka quotas can be exported:
| project | consume | produce | cluster |
|---|---|---|---|
| COST-CENTER-1 | 10 | 10 | US-EAST-MSK-1 |
| COST-CENTER-2 | 6 | 6 | US-EAST-MSK-1 |
| COST-CENTER-3 | 4 | 4 | US-EAST-MSK-1 |
| COST-CENTER-1 | 10 | 10 | US-WEST-AZURE-1 |
| COST-CENTER-5 | 10 | 10 | US-WEST-AZURE-1 |
| COST-CENTER-8 | 5 | 5 | US-WEST-AZURE-1 |
And when joined with cost reports:
| cluster | capacity | monthly_cost |
|---|---|---|
| US-EAST-MSK-1 | 20 | 2000 |
| US-WEST-AZURE-1 | 25 | 2500 |
We can produce rich real-time views in dashboards:
Kafka Connect and tenants
When the data platform tenants are also using Kafka Connect for bringing data in or out of Apache Kafka, the following
section is relevant. Additional info can be read at
KIP-411
Kafka Connect assigns a default client.id to tasks in the form:
connector-consumer-{connectorId}-{taskId} # for sink tasks
connector-producer-{connectorId}-{taskId} # for source tasks
connector-dlq-producer-{connectorId}-{taskId} # for sink tasks Dead-letter queue
That means that the above QUOTA based model for cost allocation will not work for Kafka Connect.
The solution is to specify in the worker configuration properties the producer.client.id and consumer.client.id,
as they take precedence.
cat connect-avro-distributed.properties | grep -i client
producer.client.id=COSTCENTER-1
consumer.client.id=COSTCENTER-1
Setting the above in the connect workers properties, will make the above solution feasible as, the CLIENT ID will propage to the consumers and producers of the Kafka Connect cluster:
kafka-consumer-groups --describe --group connect-nullsink --bootstrap-server localhost:909
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
connect-mongodb topic_telecom_italia 0 764 830 66 COSTCENTER-1-2d388c25-6532-43a8-b8cf-fd3bb4b06268 /10.156.0.16 COSTCENTER-1
connect-elastic topic_iot_position_reports 0 1327 1478 151 COSTCENTER-1-2d388c25-6532-43a8-b8cf-fd3bb4b06268 /10.156.0.16 COSTCENTER-1
In order to have a sound architecture around Kafka Connect multi-tenancy, keep in mind best practices,
such as the single responsibility principle. The ideal architecture is a small Kafka Connect cluster to be deployed
per data pipeline (rather than overloading a large single Kafka Connect cluster with multiple types of connectors).
How Lenses can help
Lenses can help at delivering a multi-tenant data platform in the following key areas:
Quotas / Cost Allocationto apply quotas and allocate cost with automationData centric security modelto empower people to access the data platform with a data centric security model (avoiding the security gaps of the Kafka ecosystem) and enable different roles and permissions per tenants and teamsRBAC security over Kafka Connectintroduced in Lenses version 4.1 see Kafka Connect securityDAD / Distributed Application Deploymentframework (aimed to be released in 2021), that automates the deployment of Kafka Connect pipelines natively within Kubernetes with embedded monitoring, alerting and cost allocation