Latest version: 4.3.x
SQL for exploration
When querying Kafka topic data with SQL such as
SELECT *
FROM topicA
WHERE transaction_id=123
a full scan will be executed, and the query processes the entire data on that topic to identify all records that match the transaction id.
If the Kafka topic contains a billion 50KB messages - that would require to query 50 GB of data. Depending on your network capabilities, brokers’ performance, any quotas on your account, and other parameters, fetching 50 GB of data could take some time! Even more, if the data is compressed. In the last case, the client has to decompress it before parsing the raw bytes to translate in a structure on which the query can be applied.
Does Apache Kafka have indexing capabilities?
No. Apache Kafka does not have the full indexing capabilities in the payload (indexes typically come at a high cost even on an RDBMS / DB or a system like Elastic Search), however Kafka indexes the metadata.
Can we push down predicates in Apache Kafka?
The only filters Kafka is supporting are topic, partition and offsets or timestamp.
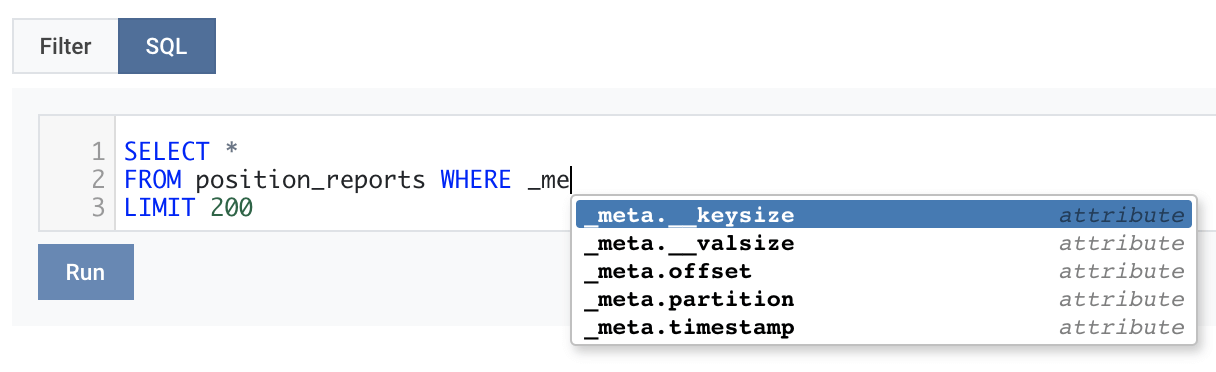
1. Partitions
SELECT *
FROM topicA
WHERE transaction_id=123
AND _meta.partition = 1
If we specify in our query that we are only interested in partition 1, and for the sake of example the above Kafka topic has 50 x partitions. Then Lenses will automatically push this predicate down, meaning that we will only need to scan 1GB instead of 50GB of data.
2. Offsets
SELECT *
FROM topicA
WHERE transaction_id=123
AND _meta.offset > 100
AND _meta.offset < 100100
AND _meta.partition = 1
If we specify the offset range and the partition, we would only need to scan the specific range of 100K messages resulting in scanning 5MB.
3. Timestamp
SELECT *
FROM topicA
WHERE transaction_id=123
AND _meta.timestamp > NOW() - "1H"
The above will query only the data added to the topic up to 1 hour ago. Thus we would query just 10MB.
4. Time-traveling
SELECT *
FROM position_reports
WHERE
_meta.timestamp > "2020-04-01" AND
_meta.timestamp < "2020-04-02"
The above will query only the data that have been added to the Kafka topic on a specific day. If we are storing 1,000 days of data, we would query just 50MB.
How can I have 100s of queries without impacting my cluster?
Lenses provides a set of rules for i) termination control ii) resource protection and iii) query management
Termination Control
SELECT * FROM topicA WHERE _key.deviceId=123 LIMIT 10
Adding a LIMIT 10 in the SQL query will result in the SQL terminating early, as soon as 10 x messages have been discovered. It’s not a perfect solution as we might never find 10 x messages, and thus perform a full scan.
SET max.query.time = 30s;
One can control the maximum time a SQL query will run for. The admin can set up a default value, and a user can override it.
SET max.size = 1M;
One can control the maximum bytes the SQL query will fetch. The admin can set up a default value, but a more advanced user can override it.
SET max.idle.time = 5s;
The above will make sure the query terminates after 5 seconds of reaching the end of the topic. The admin can set up a default value. The idea is that there is no reason to keep polling if we have exhausted the entire topic.
Resource Protection
The complete set of SQL Queries on Apache Kafka are currently being executed under a specific client-id
lenses.sql.engine and an admin can apply a global Kafka quota to restrict the maximum total network I/O.
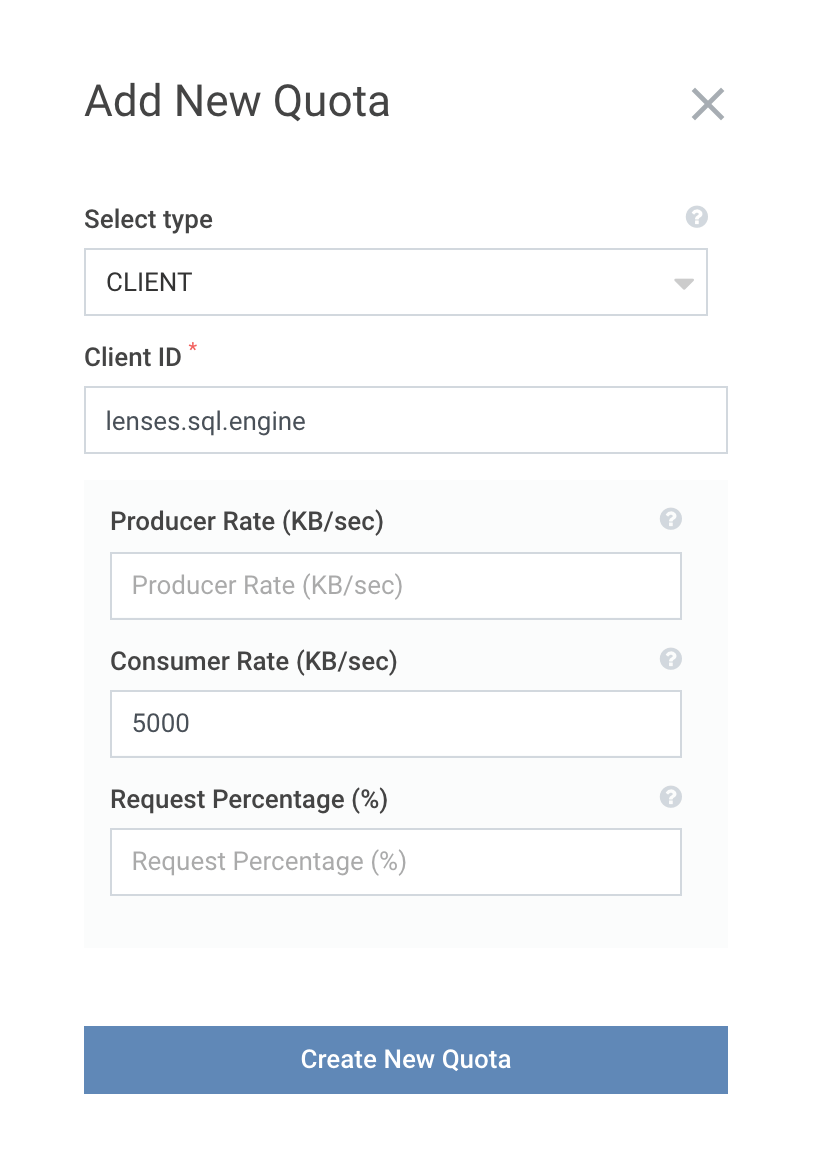
By adding a Quota on your Kafka cluster under the lenses.sql.engine CLIENT name, you can also control the global
network I/O that is allocated to all users querying Kafka data with SQL.
Query management
An admin can view all active queries with:
SHOW QUERIES
and control them, i.e., stop a running query with the following statement
KILL QUERY <id>