Latest version: 4.3.x
Time window aggregations
In this tutorial we will see how data in a
Stream
can be aggregated continuously using GROUP BY over a time window and the results are emitted downstream.
STREAM and quickly aggregate over it using the GROUP BY clause and SELECT STREAM.
More details about Aggregations and related functions can be found in the corresponding pages in the user documentation.
Setting up our example
Let’s assume that we have a topic (game-sessions) that contains data regarding remote gaming sessions by users.
Each gaming session will contain:
- the points the user achieved throughout the session
- Metadata information regarding the session:
- The country where the game took place
- The startAt the date and time the game commenced
- The endedAt the date and time the game finished
The above structure represents the value of each record in our game-sessions topic.
Additionally, each record will be keyed by user information, including the following:
- A pid, or player id, representing this user uniquely
- Some additional denormalised user details:
- a name
- a surname
- an age
Putting denormalised data in keys is not something that should be done in a production environment.
In light of the above, a record might look like the following (in json for simplicity):
{
"key":{
"pid": 1,
"name": "Billy",
"surname": "Lagrange",
"age": 30
},
"value": {
"points": 5,
"country": "Italy",
"language": "IT",
"startedAt": 1595435228,
"endedAt" : 1595441828
}
}
We can replicate such structure using SQL Studio and the following query:
CREATE TABLE game-sessions(
_key.pid int,
_key.name string,
_key.surname string,
_key.age int,
points double,
country string,
startedAt long,
endedAt long)
FORMAT (avro, avro);
We can then use SQL Studio again to insert the data we will use in the rest of the tutorial:
INSERT into game-sessions(
_key.pid,
_key.name,
_key.surname,
_key.age,
points,
country,
startedAt,
endedAt
) VALUES
(1, 'Billy', 'Lagrange', 35, 5, 'Italy', 1595524080000, 1595524085000),
(1, 'Billy', 'Lagrange', 35, 30, 'Italy', 1595524086000, 1595524089000),
(1, 'Billy', 'Lagrange', 35, 0, 'Italy', 1595524091000, 1595524098000),
(2, 'Maria', 'Rossi', 27, 50, 'Italy', 1595524080000, 1595524085000),
(2, 'Maria', 'Rossi', 27, 10, 'Italy', 1595524086000, 1595524089000),
(3, 'Jorge', 'Escudero', 27, 10, 'Spain', 1595524086000, 1595524089000),
(4, 'Juan', 'Suarez', 22, 80, 'Mexico', 1595524080000, 1595524085000),
(5, 'John', 'Bolden', 40, 10, 'USA', 1595524080000, 1595524085000);
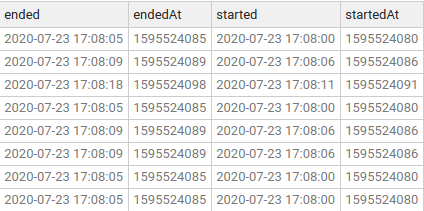
The time a game started and completed is expressed in epoch time. To see the human readable values, run this query:
SELECT
startedAt
, DATE_TO_STR(startedAt, 'yyyy-MM-dd HH:mm:ss') as started
, endedAt
, DATE_TO_STR(endedAt 'yyyy-MM-dd HH:mm:ss') as ended
FROM game-sessions;
Example 1 - Count how many games were played per user every 10 seconds
Now we can start processing the data we have inserted above.
One requirement could be to count how many games each user has played every 10 seconds.
We can achieve the above with the following query:
SET defaults.topic.autocreate=true;
SET commit.interval.ms='2000'; -- this is just to speed up the output generation in this tutorial
INSERT INTO games_per_user_every_10_seconds
SELECT STREAM
COUNT(*) as occurrences
, MAXK_UNIQUE(points,3) as maxpoints
, AVG(points) as avgpoints
FROM game-sessions
EVENTTIME BY startedAt
WINDOW BY TUMBLE 10s
GROUP BY _key
The content of the output topic, games_per_user_every_10_seconds, can now be inspected and eventually it will look similar to this:
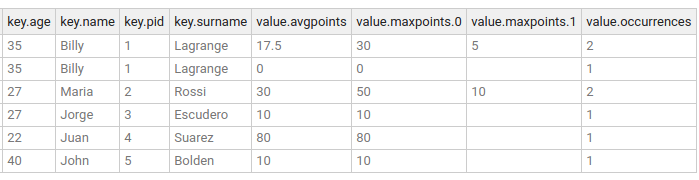
As you can see, the keys of the records did not change, but their value is the result of the specified aggregation.
The gamer Billy Lagrange has two entries because he played 2 games, the first two with a start window between 2020-07-23 17:08:00 and 2020-07-23 17:08:10(exclusive),
and the third entry between 2020-07-23 17:08:10 (inclusive) and 2020-07-23 17:08:20(exclusive)
groupby-key has been created as a compacted topic, and that is by design.All aggregations result in a Table because they maintain a running, fault-tolerant, state of the aggregation and when the result of an aggregation is written to a topic, then the topic will need to reflect these semantics (which is what a compacted topic does).
Example 2 - Count how many games were played per country every 10 seconds
We can expand on the example from the previous section. We now want to know, for each country on a 10 seconds interval, the following:
- count how many games were played
- what are the top best 3 results
All the above can be achieved with the following query:
SET defaults.topic.autocreate=true;
SET commit.interval.ms='2000'; -- this is just to speed up the output generation in this tutorial
INSERT INTO games_per_country_every_10_seconds
SELECT STREAM
COUNT(*) as occurrences
, MAXK_UNIQUE(points,3) as maxpoints
, country
FROM game-sessions
EVENTTIME BY startedAt
WINDOW BY TUMBLE 10s
GROUP BY country
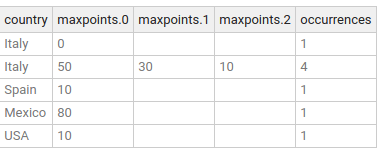
The content of the output topic, games_per_country_every_10_seconds, can now be inspected in the SQL Studio screen by running:
SELECT *
FROM games_per_country_every_10_seconds
There are 2 entries for Italy, since there is one game played at 2020-07-23 18:08:11.
Also, notice for the other entry on Italy, there are 4 occurrences and 3 max points. The reason for 4 occurrence is down to 4 games,
two each from Billy Lagrange and Maria Rossi within the 10 seconds time window between 2020-07-23 18:08:00 and 2020-07-23 18:08:10(exclusive).
Conclusion
In this tutorial you learned how to use aggregation over Streams to:
- group by the current
keyof a record - group by a field in the input record
- use a time window to define the aggregation over.
You achieved all the above using Lenses SQL engine. You can find out about the different time windows in the documentation.
Good luck and happy streaming!