Supported versions: 4.0.x
Aggregate Streams
In this tutorial we will see how data in a
Stream
can be aggregated
continuously using GROUP BY and how the aggregated results are emitted downstream.
STREAM and quickly aggregate over it using the GROUP BY clause and SELECT STREAM.
More details about Aggregations and related functions can be found in the corresponding pages in the user documentation.
Setting up our example
Let’s assume that we have a topic (game-sessions) that contains data regarding remote gaming sessions by users.
Each gaming session will contain:
- the points the user achieved throughout the session
- Metadata information regarding the session:
- The country where the game took place
- The language the user played the game in
The above structure represents the value of each record in our game-sessions topic.
Additionally, each record will be keyed by user information, including the following:
- A pid, or player id, representing this user uniquely
- Some additional denormalised user details:
- a name
- a surname
- an age
Putting denormalised data in keys is not something that should be done in a production environment.
In light of the above, a record might look like the following (in json for simplicity):
{
"key":{
"pid": 1,
"name": "Billy",
"surname": "Lagrange",
"age": 30
},
"value":{
"points": 5,
"sessionMetadata": {
"country": "Italy",
"language": "IT"
}
}
}
We can replicate such structure using SQL Studio and the following query:
CREATE TABLE game-sessions(
_key.pid int
, _key.name string
, _key.surname string
, _key.age int
, points double
, sessionMetadata.country string
, sessionMetadata.language string)
FORMAT (avro, avro);
We can then use SQL Studio again to insert the data we will use in the rest of the tutorial:
INSERT into game-sessions(
_key.pid
, _key.name
, _key.surname
, _key.age
, points
, sessionMetadata.country
, sessionMetadata.language
) VALUES
(1, 'Billy', 'Lagrange', 35, 5, 'Italy', 'IT'),
(1, 'Billy', 'Lagrange', 35, 30, 'Italy', 'IT'),
(1, 'Billy', 'Lagrange', 35, 0, 'Italy', 'IT'),
(2, 'Maria', 'Rossi', 27, 50, 'Italy', 'IT'),
(2, 'Maria', 'Rossi', 27, 10, 'Italy', 'IT'),
(3, 'Jorge', 'Escudero', 27, 10, 'Spain', 'ES'),
(4, 'Juan', 'Suarez', 22, 80, 'Mexico', 'ES'),
(5, 'John', 'Bolden', 40, 10, 'USA', 'EN'),
(6, 'Dave', 'Holden', 31, 30, 'UK', 'EN'),
(7, 'Nigel', 'Calling', 50, 5, 'UK', 'EN'),
(2, 'Maria', 'Rossi', 27, 10, 'UK', 'EN'),
(1, 'Billy', 'Lagrange', 35, 50, 'Italy', 'IT'),
(3, 'Jorge', 'Escudero', 27, 16, 'Spain', 'ES'),
(4, 'Juan', 'Suarez', 22, 70, 'Mexico', 'ES'),
(5, 'John', 'Bolden', 40, 10, 'USA', 'EN'),
(6, 'Dave', 'Holden', 31, 50, 'Italy', 'IT'),
(6, 'Dave', 'Holden', 31, 70, 'Spain', 'ES'),
(2, 'Maria', 'Rossi', 27, 70, 'Italy', 'IT'),
(1, 'Billy', 'Lagrange', 35, 50, 'Italy', 'IT')
;
Example 1 - Count how many games each user played
Now we can start processing the data we have inserted above.
One requirement could be to count how many games each user has played. Additionally, we want to ensure that, should new data come in, it will update the calculations and return the up to date numbers.
We can achieve the above with the following query:
SET defaults.topic.autocreate=true;
SET commit.interval.ms='1000'; -- this is just to speed up the output generation in this tutorial
INSERT INTO groupby-key
SELECT STREAM
COUNT(*) AS gamesPlayed
FROM game-sessions
GROUP BY _key;
The content of the output topic, groupby-key, can now be inspected in the Lenses Explore screen and it will look similar to this:
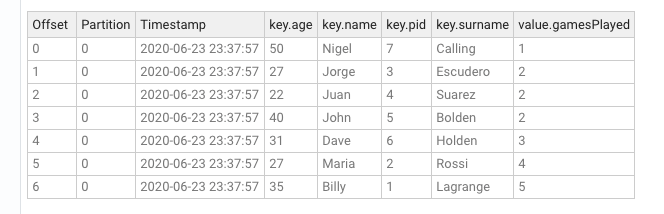
As you can see, the keys of the records did not change, but their value is the result of the specified aggregation.
groupby-key has been created as a compacted topic, and that is by design.All aggregations result in a Table because they maintain a running, fault-tolerant, state of the aggregation and when the result of an aggregation is written to a topic, then the topic will need to reflect these semantics (which is what a compacted topic does).
Example 2 - Add each user’s best results, and the average over all games
We can expand on the example from the previous section. We now want to know, for each user, the following:
- count how many games the user has played
- what are the user’s best 3 results
- what is the user’s average of points
All the above can be achieved with the following query:
SET defaults.topic.autocreate=true;
SET commit.interval.ms='1000';
INSERT INTO groupby-key-multi-aggs
SELECT STREAM
COUNT(*) AS gamesPlayed
, MAXK(points,3) as maxpoints
, AVG(points) as avgpoints
FROM game-sessions
GROUP BY _key;
The content of the output topic, groupby-key-multi-aggs, can now be inspected in the Lenses Explore screen, and it will look similar to this:
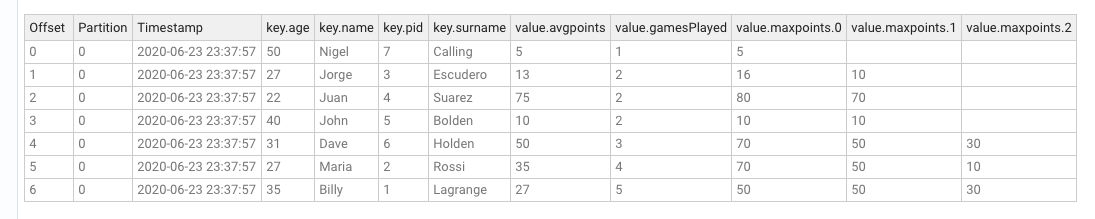
Example 3 - Gather statistics about users playing from the same country and using the same language
Our analytics skills are so good that we are now asked for more.
We now want to calculate the same statistics as before, but grouping together players that played from the same country and used the same language.
Here is the query for that:
SET defaults.topic.autocreate=true;
SET commit.interval.ms='1000';
INSERT INTO groupby-country-and-language
SELECT STREAM
COUNT(*) AS gamesPlayed
, MAXK(points,3) as maxpoints
, AVG(points) as avgpoints
, sessionMetadata.language as sessionLanguage
FROM game-sessions
GROUP BY
sessionMetadata.country
, sessionMetadata.language;
The content of the output topic, groupby-country-and-language, can now be inspected in the Lenses Explore screen and it will look similar to this:

sessionMetadata.language as sessionLanguage in the query.We could do that because
sessionMetadata.language is part of the GROUP BY clause.LSQL only supports Full Group By mode, so if the projected field is not part of the
GROUP BY clause, the query will be invalid.
Example 4 - Filtering aggregation data
One final scenario we will cover in this tutorial is when we want to filter some data within our aggregation.
There are two possible types of filtering we might want to do, when it comes to aggregations:
- Pre-aggregation: we want some rows to be ignored by the grouping, so they will not be part of the calculation done by aggregation functions. In these scenarios we will use the
WHEREclause. - Post-aggregation: we want to filter the aggregation results themselves, so that those aggregated records which meet some specified condition are not emitted at all. In these scenarios we will use the
HAVINGclause.
Let’s see an example.
We want calculate the usual statistics from the previous scenarios, but grouping by the session language only.
However, we are interested only in languages that are used a small amount of times (we might want to focus our marketing team’s effort there); additionally, we are aware that some users have been using VPNs to access our platform, so we want to exclude some records from our calculations, if a given user appeared to have played from a given country.
For the sake of this example, we will:
- Show statistics for languages that are used less than 9 times
- Ignore sessions that
Davemade fromSpain(because we know he was not there)
The query for all the above is:
SET defaults.topic.autocreate=true;
SET commit.interval.ms='1000';
INSERT INTO groupby-language-filtered
SELECT STREAM
COUNT(*) AS gamesPlayed
, MAXK(points,3) as maxpoints
, AVG(points) as avgpoints
FROM game-sessions
WHERE _key.name != 'Dave'
OR sessionMetadata.country != 'Spain'
GROUP BY sessionMetadata.language
HAVING gamesPlayed < 9;
The content of the output topic, groupby-language-filtered, can now be inspected in the Lenses Explore screen and it will look similar to this:

IT (which is the only language that has 9 sessions in total) appears in the output but without any data in the value section.This is because aggregations are Tables, and the key
IT used to be present (while it was lower than 9), but then it was removed. Deletion is expressed, in Tables, by setting the value section of a record to null, which is what we are seeing here.
Conclusion
In this tutorial you learned how to use aggregation over Streams to:
- group by the current
keyof a record - calculate multiple results in a single processor
- group by a combination of different fields of the input record
- filtering both the data that is to be aggregated, and the one that will be emitted by the aggregation itself
You achieved all the above using Lenses SQL engine.
You can now proceed to learn about more complex scenarios like aggregation over Tables and windowed aggregations.
Good luck and happy streaming!