Latest version: 4.3.x
Automate SQL processors creation
In this tutorial, we will see how to automate the process for creating SQL processors.
Setting up our example
The requirement is to automate an SQL processor’s deployment, including creating the topic and associated data schema. We have an input topic, let’s call it ‘input,’ the topic message key is text(i.e., STRING), and the message value is an Avro with this schema:
{
"type": "record",
"name": "ConnectDefault",
"namespace": "io.lenses.connect.avro",
"fields": [
{
"name": "EVENTID",
"type": "string"
},
{
"name": "EVENTDATETIME",
"type": "string"
},
{
"name": "CLIENTID",
"type": "string"
},
{
"name": "CUSTOMERCATEGORY",
"type": "string"
},
{
"name": "CUSTOMERID",
"type": "string"
},
{
"name": "ENTITYID",
"type": "string"
},
{
"name": "EVENTCORRELATIONID",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "EVENTSOURCE",
"type": "string"
},
{
"name": "SUPERPRODUCTID",
"type": "string"
},
{
"name": "TENANTID",
"type": "string"
},
{
"name": "TREATMENTCODE",
"type": [
"null",
"string"
],
"default": null
},
{
"name": "SAPREASONCODE",
"type": "string"
},
{
"name": "TRXAMOUNT",
"type": "string"
},
{
"name": "TRXCODE",
"type": "string"
},
{
"name": "TRXDESCRIPTION",
"type": "string"
},
{
"name": "SourceType",
"type": [
"null",
"string"
],
"default": null
}
]
}
Then we have the SQL processor code to rename and re-align the fields:
SET defaults.topic.autocreate=true;
INSERT INTO output1
SELECT STREAM
EVENTID as EventID
, EVENTDATETIME as EventDateTime
, EVENTSOURCE as EventSource
, TENANTID as TenantId
, ENTITYID as EntityId
, CUSTOMERID as CustomerID
, CLIENTID as ClientID
, SUPERPRODUCTID as SuperProductID
, CUSTOMERCATEGORY as CustomerCategory
, SAPREASONCODE as SAPReasonCode
, TRXAMOUNT as TrxAmount
, TRXDESCRIPTION as TrxDescription
, TREATMENTCODE as TreatmentCode
, SourceType
FROM input
Setting up the environment
We need a Lenses Security Group defining the permissions our script will require, and also a Service Account linked to that Security Group. Please, refer to the Service Accounts docs for further details.
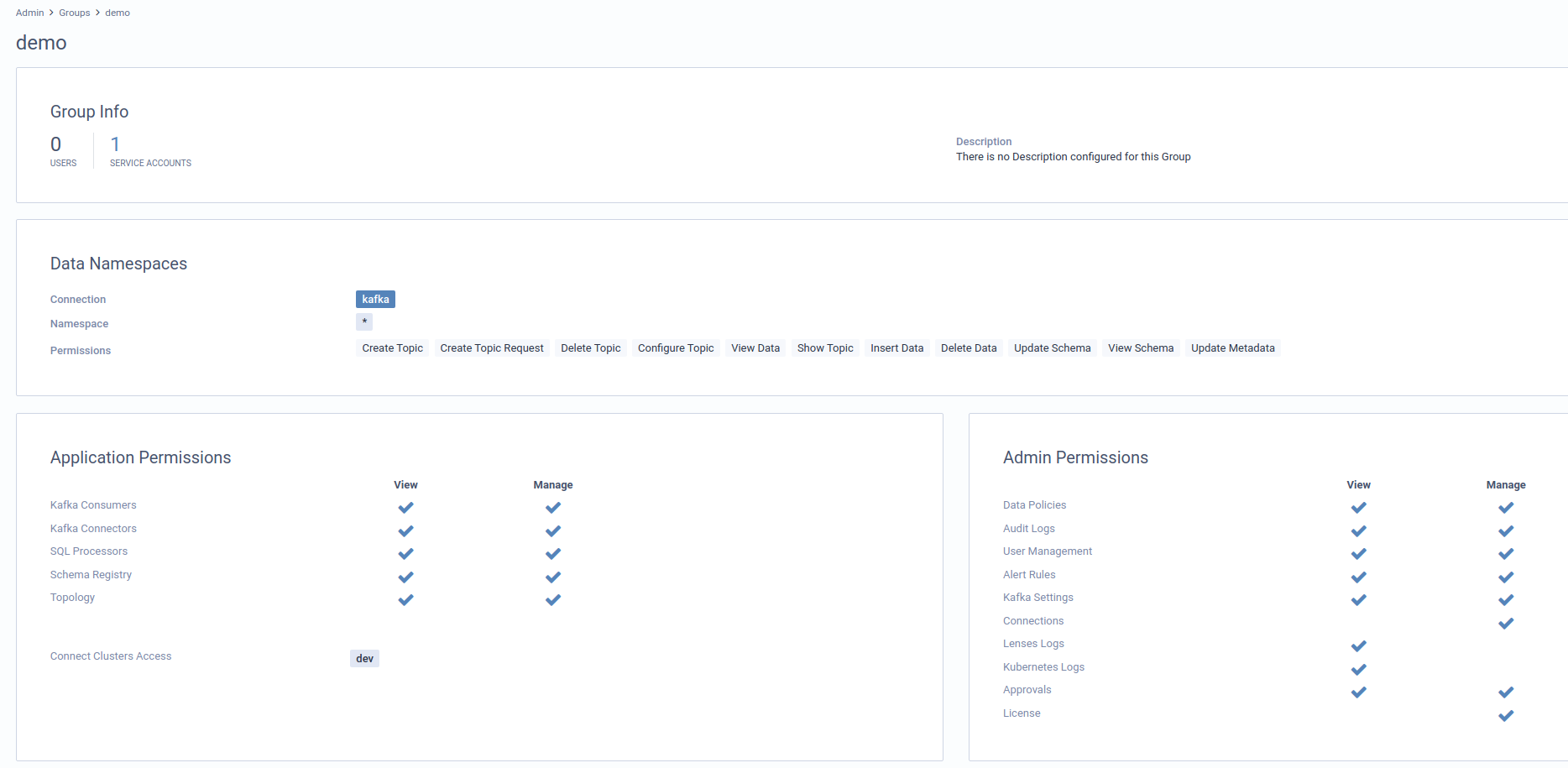
Step 1 - Create the security group
Navigate to the Admin section using the top bar navigation. From the left navigation system, navigate to Groups and add a new group. For the matter of this example, we are creating one with full access to any topic in the Kafka cluster. Here are the details:
Group name: demo
Namespaces: *
Application Permissions: Select All
Admin Permissions: Select All
Step 2 - Create the service account
From there follow the left navigation system to go to Service accounts page, and add a new entry:
Service Account Name: demo
Owner: leave it empty
Groups: demo
Leave the autogenerate option enabled
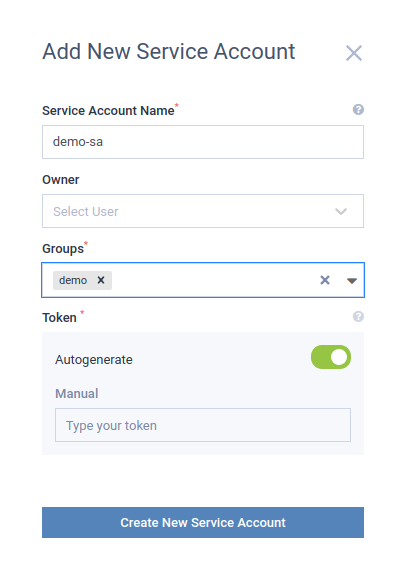
Grab the token provided for the service account; following steps will use it.
Pipeline creation automation
Step 1 - Create the topic and the schema
Lenses SQL processors require schema even if they are not Avro. Creating a topic that uses AVRO for the message key or value will first register it with Schema Registry.
First, let’s create the request payload. Save this JSON to a file named body.json
{
"name": "input",
"replication": 1,
"partitions": 3,
"configs": {},
"format": {
"key": {
"format": "STRING"
},
"value": {
"format": "AVRO",
"schema": "{\"type\":\"record\",\"name\":\"ConnectDefault\",\"namespace\":\"io.lenses.connect.avro\",\"fields\":[{\"name\":\"EVENTID\",\"type\":\"string\"},{\"name\":\"EVENTDATETIME\",\"type\":\"string\"},{\"name\":\"CLIENTID\",\"type\":\"string\"},{\"name\":\"CUSTOMERCATEGORY\",\"type\":\"string\"},{\"name\":\"CUSTOMERID\",\"type\":\"string\"},{\"name\":\"ENTITYID\",\"type\":\"string\"},{\"name\":\"EVENTCORRELATIONID\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"EVENTSOURCE\",\"type\":\"string\"},{\"name\":\"SUPERPRODUCTID\",\"type\":\"string\"},{\"name\":\"TENANTID\",\"type\":\"string\"},{\"name\":\"TREATMENTCODE\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"SAPREASONCODE\",\"type\":\"string\"},{\"name\":\"TRXAMOUNT\",\"type\":\"string\"},{\"name\":\"TRXCODE\",\"type\":\"string\"},{\"name\":\"TRXDESCRIPTION\",\"type\":\"string\"},{\"name\":\"SourceType\",\"type\":[\"null\",\"string\"],\"default\":null}]}"
}
}
}
Paste the content after running this command
cat > body.json
[Paste the JSON above]
[Hit Enter then CTRL+C]
Lenses authentication and authorization require a token passed via X-Kafka-Lenses-Token. Since we created the service account entry, this token is already available.
curl --header "Content-Type: application/json" \
--header "X-Kafka-Lenses-Token: <service account>" \
-i -X POST \
--data @body.json \
http://localhost:24015/api/v1/kafka/topic
Step 2 - Create the SQL processor
It is assumed the SQL processor deployment mode is IN_PROC - Lenses also supports Kafka Connect and Kubernetes. For more details about the other modes, follow this link .
Before we issue the CURL command, let’s create the request body JSON.
Please refer to the version you are using in your Lenses installation.
Lenses 5.0+
{
"name": "myProcessor",
"sql": "SET defaults.topic.autocreate=true;\n\nINSERT INTO output1\nSELECT STREAM \n EVENTID as EventID\n , EVENTDATETIME as EventDateTime\n , EVENTSOURCE as EventSource\n , TENANTID as TenantId\n , ENTITYID as EntityId\n , CUSTOMERID as CustomerID\n , CLIENTID as ClientID\n , SUPERPRODUCTID as SuperProductID\n , CUSTOMERCATEGORY as CustomerCategory\n , SAPREASONCODE as SAPReasonCode\n , TRXAMOUNT as TrxAmount\n , TRXDESCRIPTION as TrxDescription\n , TREATMENTCODE as TreatmentCode\n , SourceType\nFROM input",
"description": "This is just a sample processor",
"deployment": {
"mode": "IN_PROC"
},
"tags": ["tag1", "tag2"]
}
Note: For the full API requirements for other deployment modes, please check the API docs
cat > processor.json
[Paste the json above]
[Hit Enter then CTRL+C]
curl --header "Content-Type: application/json" \
--header "X-Kafka-Lenses-Token: <service account>" \
-i -X POST \
--data @processor.json \
http://localhost:24015/api/v2/streams
Lenses <5.0
{
"name": "myProcessor",
"runnerCount": 1,
"sql": "SET defaults.topic.autocreate=true;\n\nINSERT INTO output1\nSELECT STREAM \n EVENTID as EventID\n , EVENTDATETIME as EventDateTime\n , EVENTSOURCE as EventSource\n , TENANTID as TenantId\n , ENTITYID as EntityId\n , CUSTOMERID as CustomerID\n , CLIENTID as ClientID\n , SUPERPRODUCTID as SuperProductID\n , CUSTOMERCATEGORY as CustomerCategory\n , SAPREASONCODE as SAPReasonCode\n , TRXAMOUNT as TrxAmount\n , TRXDESCRIPTION as TrxDescription\n , TREATMENTCODE as TreatmentCode\n , SourceType\nFROM input",
"settings": {}
}
cat > processor.json
[Paste the json above]
[Hit Enter then CTRL+C]
curl --header "Content-Type: application/json" \
--header "X-Kafka-Lenses-Token: <service account>" \
-i -X POST \
--data @processor.json \
http://localhost:24015/api/v1/streams
Result and Conclusion
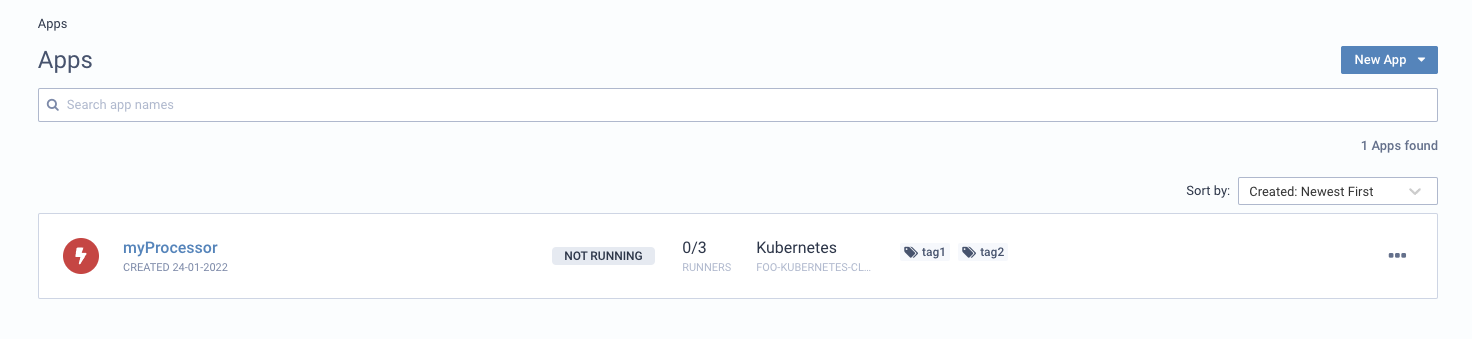
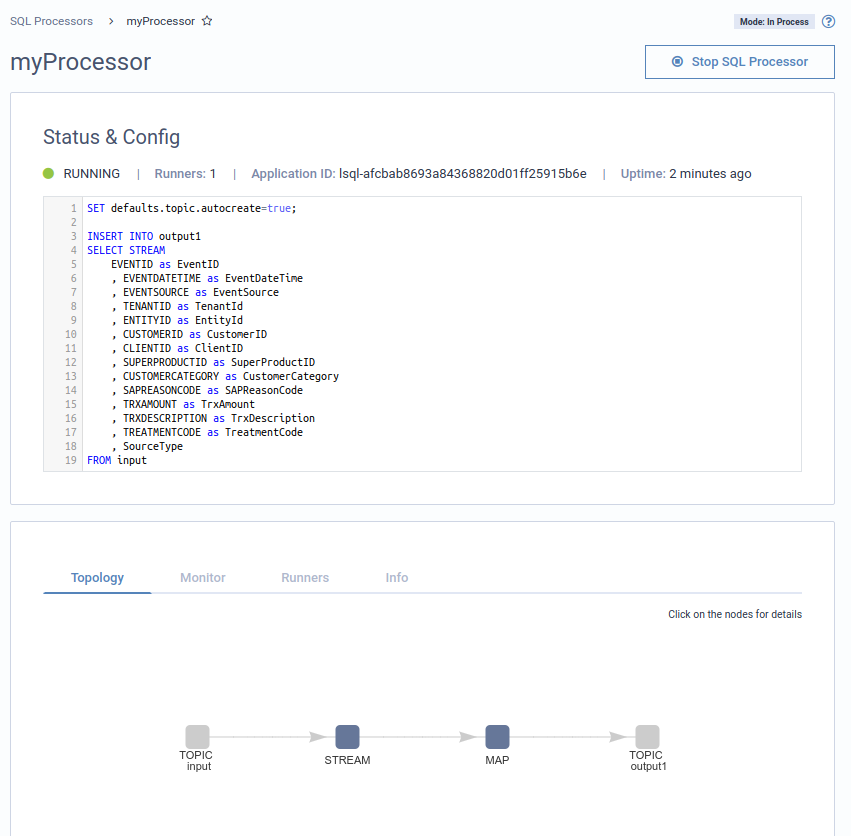
Once the last curl command is executed, Lenses will have the processor ready for processing your data:
Lenses 5.0+
Lenses < 5.0
In this tutorial, you learned how to automate your data pipelines and even integrate your CI/CD with Lenses to create your SQL processors automatically.
- Create a topic and its associated schema via the Lenses HTTP endpoints
- Create the SQL processor via the Lenses HTTP endpoints
Good luck and happy streaming!