Latest version: 4.3.x
Join 3 Kafka topics
In this example, we will show how to aggregate three Kafka topics by using Streaming SQL processors.
We will be aggregating:
employee_dictionary: messages contain the name, surname and employee idcontact_info: messages contain the email and other contact informationaddress: message contain address details
The events are streamed into Kafka from an external database, and the goal is to aggregate all employee information into a single topic.
Streaming SQL enrichment on Apache Kafka
With the following SQL function, we can wrangle events that are sent to the three Kafka topics, (as they are sourced upstream from a Database using a CDC Change Data Capture Process Connector).
SET defaults.topic.autocreate=true;
WITH AdressInfoTable AS (
SELECT TABLE
metadata.masterKey as masterKey
, employeeAddress
FROM employee_address_events
);
WITH ContactInfoTable AS (
SELECT TABLE
metadata.masterKey as masterKey
, employeeContactInfo
FROM employee_contact_info_events
);
WITH productTable AS (
SELECT TABLE
p.masterKey as masterKey
, c.employeeContactInfo
, p.employeeAddress
FROM AdressInfoTable AS p
INNER JOIN ContactInfoTable AS c
ON p.masterKey = c.masterKey
);
INSERT INTO employee_enriched
SELECT TABLE
productTable.masterKey
, employee_dictionary.employee.firstName as firstName
, employee_dictionary.employee.lastName as lastName
, employee_dictionary.employee.employeeId as employeeId
, productTable.employeeContactInfo
, productTable.employeeAddress
FROM employee_dictionary INNER JOIN productTable
ON employee_dictionary._key = productTable.masterKey;
The streaming topology that we want to achieve is effectively the bellow:
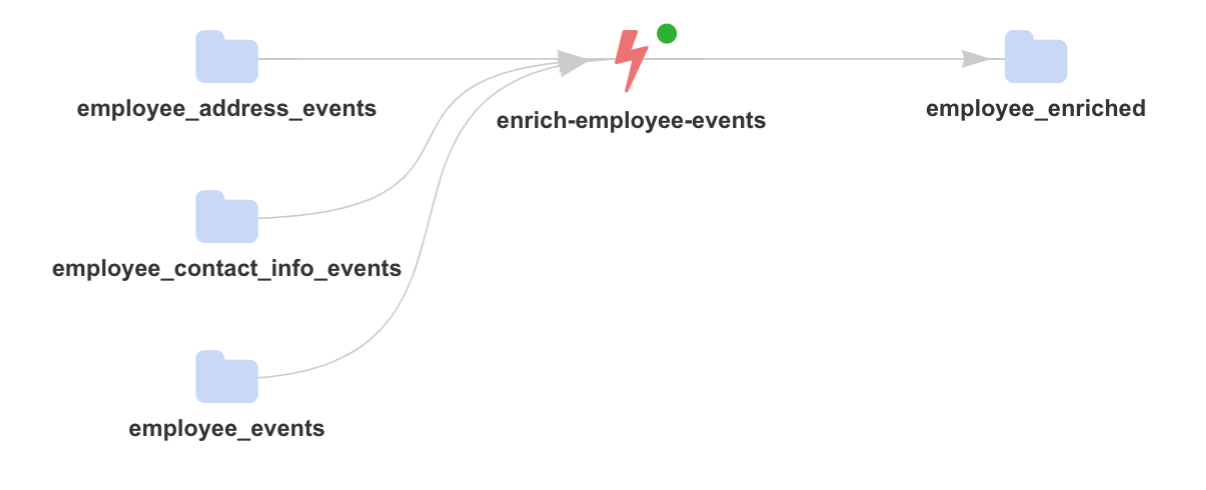
Testing data
To simplify our testing process and run the above example in less than 60 seconds, we will be using SQL to create and populate the three Apache Kafka topics:
CREATE TOPIC employee_dictionary
CREATE TABLE employee_dictionary (
_key string
, metadata.eventType string
, metadata.entityType string
, employee.firstName string
, employee.lastName string
, employee.employeeId string
)
FORMAT(string, json)
PROPERTIES(partitions=1, replication=1, compacted=true);
Note: The employee_dictionary topics is compacted since it hosts the name and employee id.
POPULATE TOPIC employee_dictionary
INSERT INTO employee_dictionary(
_key
, metadata.eventType
, metadata.entityType
, employee.firstName
, employee.lastName
, employee.employeeId
) VALUES
("196ea70d-b7f2-43ac-a15a-fa1774f7488a","employee_created","employee","Ollie","Johnson","30-6107836"),
("9d7f69e9-9ea0-4785-903a-d09d0f8342b7","employee_created","employee","Harry","Williamson","25-7784327");
CREATE TOPIC employee_contact_info_events
CREATE TABLE employee_contact_info_events (
_key string
, metadata.masterKey string
, metadata.eventType string
, metadata.entityType string
, employeeContactInfo.type string
, employeeContactInfo.preferencePriority int
, employeeContactInfo.value string
)
FORMAT(string, json)
PROPERTIES(partitions=1, replication=1, compacted=false);
POPULATE TOPIC employee_contact_info_events
INSERT INTO employee_contact_info_events(
_key
, metadata.masterKey
, metadata.eventType
, metadata.entityType
, employeeContactInfo.type
, employeeContactInfo.preferencePriority
, employeeContactInfo.value
) VALUES
("55f3730f-731b-45ae-8f06-1a333ab83210","196ea70d-b7f2-43ac-a15a-fa1774f7488a","employee_contact_info_added","employee_contact_info","email",1,"ollie@yahoo.com"),
("57432ae9-fa30-478e-aa87-12d026cd2bad","9d7f69e9-9ea0-4785-903a-d09d0f8342b7","employee_contact_info_added","employee_contact_info","email","1","harry@olson-reed.org");
CREATE TOPIC employee_address_events
CREATE TABLE employee_address_events(
_key string
, metadata.masterKey string
, metadata.eventType string
, metadata.entityType string
, employeeAddress.type string
, employeeAddress.address string
, employeeAddress.city string
, employeeAddress.state string
, employeeAddress.zipCode int
)
FORMAT(string, json)
PROPERTIES(partitions=1, replication=1, compacted=false);
POPULATE TOPIC employee_address_events
INSERT INTO employee_address_events(
_key
, metadata.masterKey
, metadata.eventType
, metadata.entityType
, employeeAddress.type
, employeeAddress.address
, employeeAddress.city
, employeeAddress.state
, employeeAddress.zipCode
) VALUES
("479b6e61-1e3a-457c-a26f-2c7ef7d35f5b","196ea70d-b7f2-43ac-a15a-fa1774f7488a","employee_address_added","employee_address","physical","3415 Brookdale Drive","Santa Clara","CA","95051"),
("23cfb3a6-cebb-4746-a7ee-6cd64b527e1c","9d7f69e9-9ea0-4785-903a-d09d0f8342b7","employee_address_added","employee_address","physical","835 Shiloh Court","Redding","CA","96003");
Data enrichment
Now that we have created the topics and populated them, we are ready to execute our streaming SQL function to create enriched information and write it into a new topic.
A Kafka Streams application executing the above SQL and deployed automatically (in ~ 2 seconds) onto Kubernetes will result into the following performance/monitoring information:
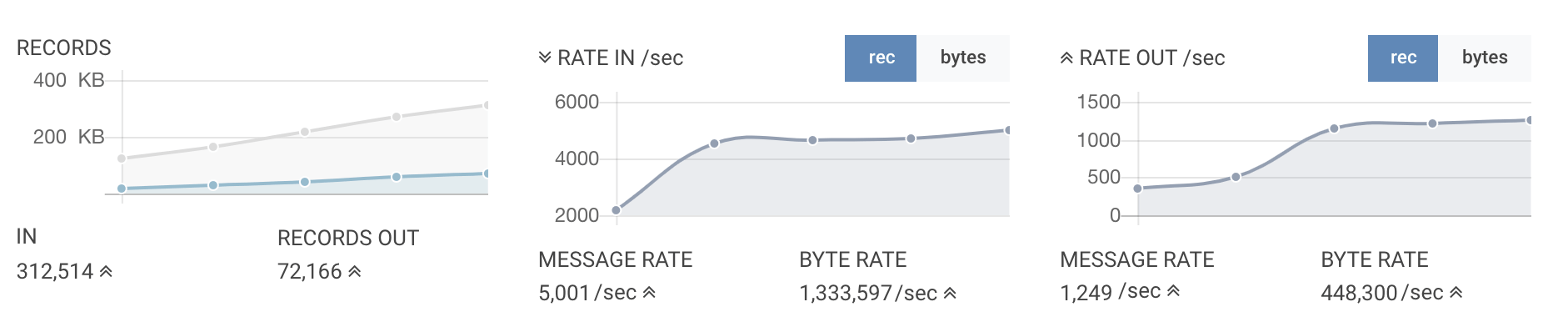
In just a few seconds, we have already enriched hundreds of thousand of events:
