Latest version: 4.3.x
Enrich credit card streaming data
This example shows a running windowed calculation. It continuously aggregates credit card transaction attempts where the card has been blocked.
Streaming analytics with SQL
With the following SQL function, we will aggregate and analyze streaming events from Apache Kafka.
SET defaults.topic.autocreate=true;
SET commit.interval.ms='10000';
WITH tableCards AS (
SELECT TABLE *
FROM example_cc_data
WHERE currency = 'EUR'
);
WITH stream AS (
SELECT STREAM
p.currency,
p.amount
FROM example_cc_payments AS p
INNER JOIN tableCards AS c
ON p._key = c._key
WHERE c.blocked = true
);
INSERT INTO example_join
SELECT STREAM
currency AS currency
, sum(amount) AS total
, count(*) AS usage
FROM stream
WINDOW BY TUMBLE 5s
GROUP BY currency
The streaming topology that we want to achieve is effectively the bellow:
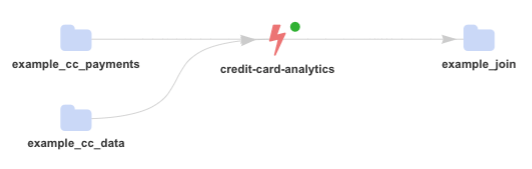
Underling Kafka Streams application which continuously executes the code looks like:
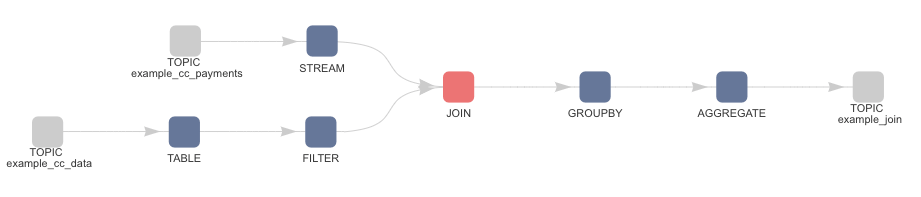
Let us have a look at the above streaming SQL.
Apart from INSERT, which is self-explanatory, we have
- SET
- WITH tableCards
- SELECT STREAM
The SET autocreate=true; at the beginning of the SQL allows Lenses to create the product topic defined after INSERT if it does not exist.
We are also using WITH <tableName> to create a new table with only the _key & blocked fields from example_cc_data topic, which in this example is our user’s dictionary. We also filter only records that have EUR as the currency.
The example_cc_payments topic is our source of payment events. In the SELECT STREAM, we define a stream that does an INNER JOIN between exaple_cc_payments and tableCards.
All records within 5 seconds tumble window that belongs to a customer with blocked status are grouped and written to the exaple_join topic.
Testing data
To simplify our testing process and to run the above example in less than 60 seconds, we will be using SQL to create and populate the Apache Kafka topics:
CREATE TOPIC example_cc_data
CREATE TABLE example_cc_data (
_key string
, number string
, customerFirstName string
, customerLastName string
, country string
, currency string
, blocked boolean
)
FORMAT(string, avro)
PROPERTIES(partitions=2, replication=1, compacted=true);
When run in SQL Studio, the above SQL will create a topic called example_cc_data with two partitions, replication factor of one and
compaction set to true.
We also define the structure of the topic. The serde for the records Value is set to Avro and serde for the Key to string. For the Avro, we should
note that Lenses also takes care of the Schema for us (given that a schema registry has been configured with Lenses). If you navigate to
the schema registry view in Lenses, you will notice that a schema example_cc_data-value has been created and has the exact structure as the
one we defined above.
POPULATE TOPIC example_cc_data
INSERT INTO example_cc_data(
_key
, number
, customerFirstName
, customerLastName
, country
, currency
, blocked
) VALUES
("5162258362252394","5162258362252394","April","Paschall","GBR","GBP",false),
("5290441401157247","5290441401157247","Charisse","Daggett","USA","USD",false),
("5397076989446422","5397076989446422","Gibson","Chunn","USA","USD",true),
("5248189647994492","5248189647994492","Hector","Swinson","NOR","NOK",false),
("5196864976665762","5196864976665762","Booth","Spiess","CAN","CAD",false),
("5423023313257503","5423023313257503","Hitendra","Sibert","SWZ","CHF",false),
("5337899393425317","5337899393425317","Larson","Asbell","SWE","SEK",false),
("5140590381876333","5140590381876333","Zechariah","Schwarz","GER","EUR",true),
("5524874546065610","5524874546065610","Shulamith","Earles","FRA","EUR",true),
("5204216758311612","5204216758311612","Tangwyn","Gorden","GBR","GBP",false),
("5336077954566768","5336077954566768","Miguel","Gonzales","ESP","EUR",true),
("5125835811760048","5125835811760048","Randie","Ritz","NOR","NOK",true),
("5317812241111538","5317812241111538","Michelle","Fleur","FRA","EUR",true),
("5373595752176476","5373595752176476","Thurborn","Asbell","GBR","GBP",true),
("5589753170506689","5589753170506689","Noni","Gorden","AUT","EUR",false),
("5588152341005179","5588152341005179","Vivian","Glowacki","POL","EUR",false),
("5390713494347532","5390713494347532","Elward","Frady","USA","USD",true),
("5322449980897580","5322449980897580","Severina","Bracken","AUT","EUR",true);
The above SQL will populate the topic we created before we some data. We should note that you can use Lenses API to insert records as easy as we did above. This way, your cronjob scripts, and other background processes can call an API and write data to Apache Kafka without requiring you to setup a Kafka producer.
CREATE TOPIC example_cc_payments
CREATE TABLE example_cc_payments (
id string
, amount decimal
, currency string
, creditCardId string
)
FORMAT(string, avro)
PROPERTIES(partitions=1, replication=1, compacted=false);
The above SQL creates example_cc_payments topic, which will store all payment events. As you can see, the topic is not compacted.
A single customer can make multiple payments, but a customer should exist only once in our topic (example_cc_data).
POPULATE TOPIC example_cc_payments
INSERT INTO example_cc_payments (
_key
, id
, amount
, currency
, creditCardId
) VALUES
("5373595752176476", "txn1", 100.2, "GBP", "5373595752176476"),
("5322449980897580", "txn2", 51.2, "EUR", "5322449980897580"),
("5140590381876333", "txn2", 389.1, "EUR", "5140590381876333"),
("5589753170506689", "txn1", 11.2, "GBP", "5589753170506689"),
("5336077954566768", "txn2", 559.8, "EUR", "5336077954566768"),
("5337899393425317", "txn2", 221.50, "SEK", "5337899393425317");
Same logic as the previews INSERT example.
Verify our data
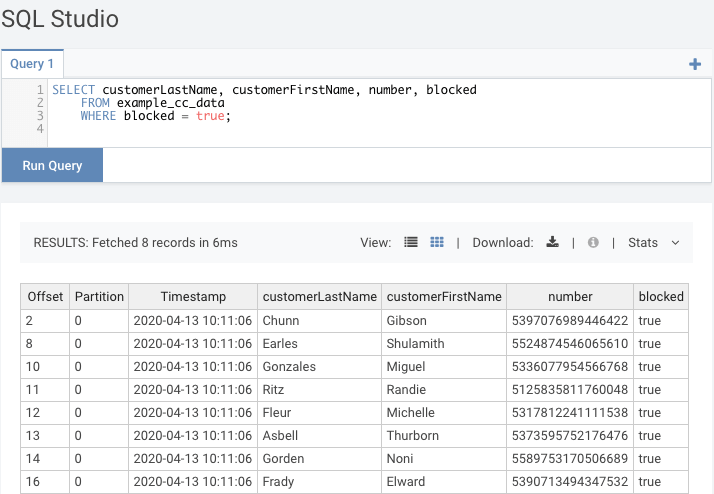
Let’s use SQL to validate the messages:
SELECT
customerLastName
, customerFirstName
, number
, blocked
FROM example_cc_data
WHERE blocked = true
In the testing data 8 out of the 18 credit card transactions have the card blocked:
Streaming analysis
With the topics and data available, the SQL processor can be created and started.