Latest version: 4.3.x
Data Policies
- What are Data Policies, and their basic concepts
- How to access and manage Data Policies through the APU, CLI and UI
Basic Concepts
Data policies enable compliance with regulations such as GDPR, CCPA, or HIPAA.
Use Data Policies to obfuscate data retrieved from users via the UI, CLI, or API without affecting how the underlying data is stored.
Lenses follows the standards of the National Institute of Standards and Technology (NIST),
and Policies offer the ability to obfuscate sensitive fields of your datasets. The governance is global,
across all users and clients including API, CLI, UI, and SQL.
The Data Policy’s principal properties are Redaction, Category, Impact, Datasets, and Fields.
Redaction
The rule to use to obfuscate a field. Lenses applies data obfuscation to all data access requests, and several data types/structures are supported, including Strings, Numbers, Emails for every data format (JSON, XML, AVRO or Protobuf).
Global
These rules will work regardless of the type.
| Rules | Explanation |
|---|---|
| None | Track sensitive data, but do not protect them. |
| All | Mask the entire value. |
Special
These rules will work only on
Alphanumericvalues.
| Rules | Explanation |
|---|---|
| Mask email address, showing the domain name. |
Strings
These rules will work only on
Alphanumericvalues.
| Rules | Explanation |
|---|---|
| Last-1 | Display the last 1 characters of the value. |
| Last-2 | Display the last 2 characters of the value. |
| Last-3 | Display the last 3 characters of the value. |
| Last-4 | Display the last 4 characters of the value. |
| First-1 | Display the first 1 characters of the value. |
| First-2 | Display the first 2 characters of the value. |
| First-3 | Display the first 3 characters of the value. |
| First-4 | Display the first 4 characters of the value. |
| Initials | Display the first letter of each word. |
Numbers
Keep in mind that values that are not numeric will not be affected by these Policies. Strings that contain numbers will not be affected either.
| Rules | Explanation |
|---|---|
| Number-to-zero | Replace a numeric value with 0. |
| Number-to-negative-one | Replace a numeric value with -1. |
| Number-to-null | Replace a numeric value with null. |
Category
What is your Data’s category for sensitivity? Any value can be entered here, based on what makes sense for a particular organisation. You can find more information about Data Classification here , but here are a few popular options.
| Data Classification | Explanation |
|---|---|
| PII | Personal Identifible Infomation. |
| HIPPA | Protected Health Infomation. |
Impact
How important is the Data for the Business? It refers to the sensitivity level of the information to be stored and processed.
| Impact Level | Explanation |
|---|---|
| HIGH | Information such as PII(name,religion..) |
| MEDIUM | Information such as Assets(productIds..) |
| LOW | Information such as Linkables(Dates..) |
Datasets
You can choose to encapsulate your Policy, for a specific Dataset(s). This is a wildcard option, and if not specified, it will apply to all Datasets.
| Wildcard Rule | Explanation |
|---|---|
*word | Will match all Datasets that end with word |
word* | Will match all Datasets that start with word |
*word* | Will match all Datasets that contain the word |
Fields
Which field(s), should we target and obfuscate. This is a also a wildcard option.
There are a few advanced fields specifications that we need to be careful with.
Nested Fields
In the case of nested data, it is possible to specify nested fields using the “.” character.
For example, if your “customers” Dataset has a field called information which contains a field called name,
it is possible to specify the field information.name, so that only that particular field is obfuscated, instead of every field.
Note that obfuscation is only performed on nodes without children. Continuing with the example above,
information.namewill be obfuscated, but if we attempt to apply it toinformation, it will not be affected, as it has child properties.
Clashing Policies
In the event of two policies matching a given field, the more specific one will be applied. For example, if there is a policy for name with a redaction of First-4 and a policy for customers.information.name with a redaction of Initials, the latter will be applied.
Please note that
wildcardsand dataset rules do not affect this.
Advanced Wildcards
It is also possible to specify wildcards using the * character so that i*n.name will match both information.name and installation.name.
As . is considered a field separator, such that a wildcard will not match it.
So i*n.name will match information.namebut will not match information.details.name.
Note on Kafka topics
Keep in mind that for Kafka Topics, we apply the Policy to both Key and Value,
and the policy will apply to each of these if they contain the corresponding field.
API
Alongside with Lenses UI, the administration of data policies may be performed using the Lenses API. For more information, please visit the API Docs
CLI
The CLI provides the full CRUD Operations for Data Policies. If you are interested in the CLI, you can find more info here .
# Export policies
export policies --resource-name policyName
# Import policies
import policies --dir /prod-dir --ignore-errors
UI
It allows you to List, Create, View Details, Update and of course Delete Data Policies
Listing Policies
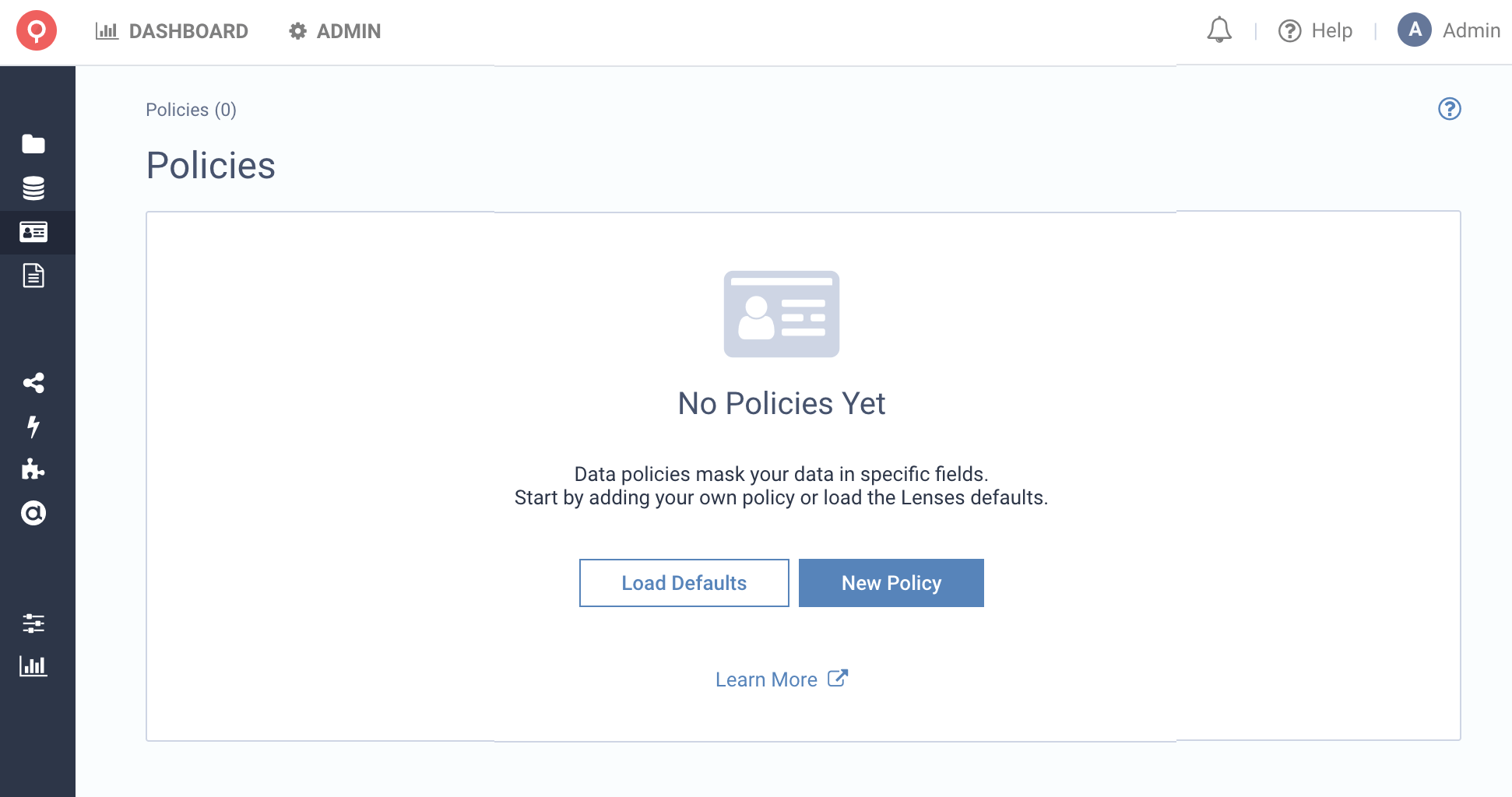
No data policies are enabled by default. Import automatically recommended data policies or create a new one.
Once your Data Policies have been created, search, and filters allow you to find Data Policies, by Field,
Dataset and Applications.
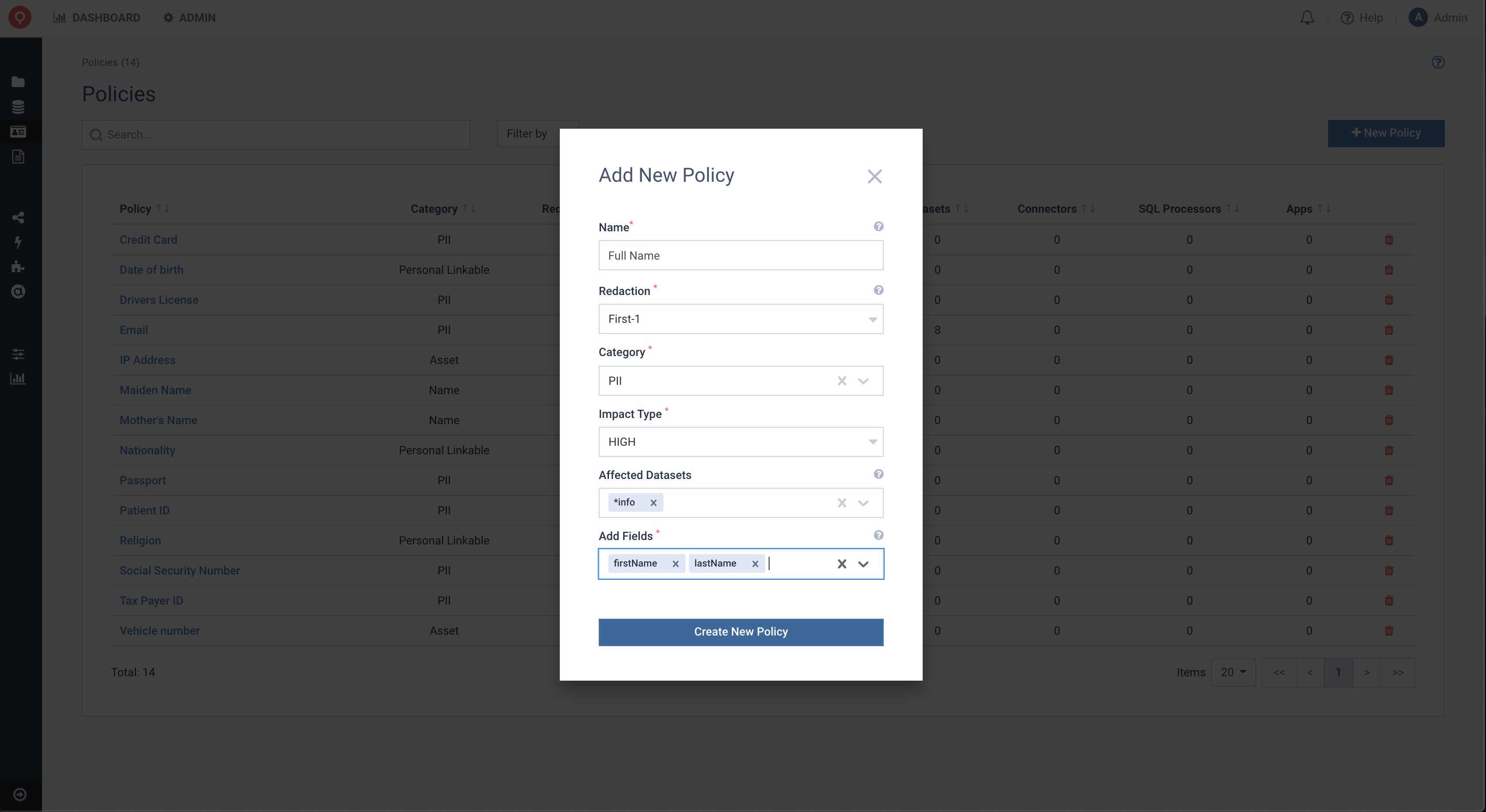
Create New Policy
We can create Policies by clicking the New Policy button. Let’s create a Policy called Full Name,
which protects PII information by showing only the first Letter First-1 Redaction, for either first or last names.
The obfuscation is applied to all Datasets, with names that end with the word info
and apply the obfuscation to the fields firstName and lastName.
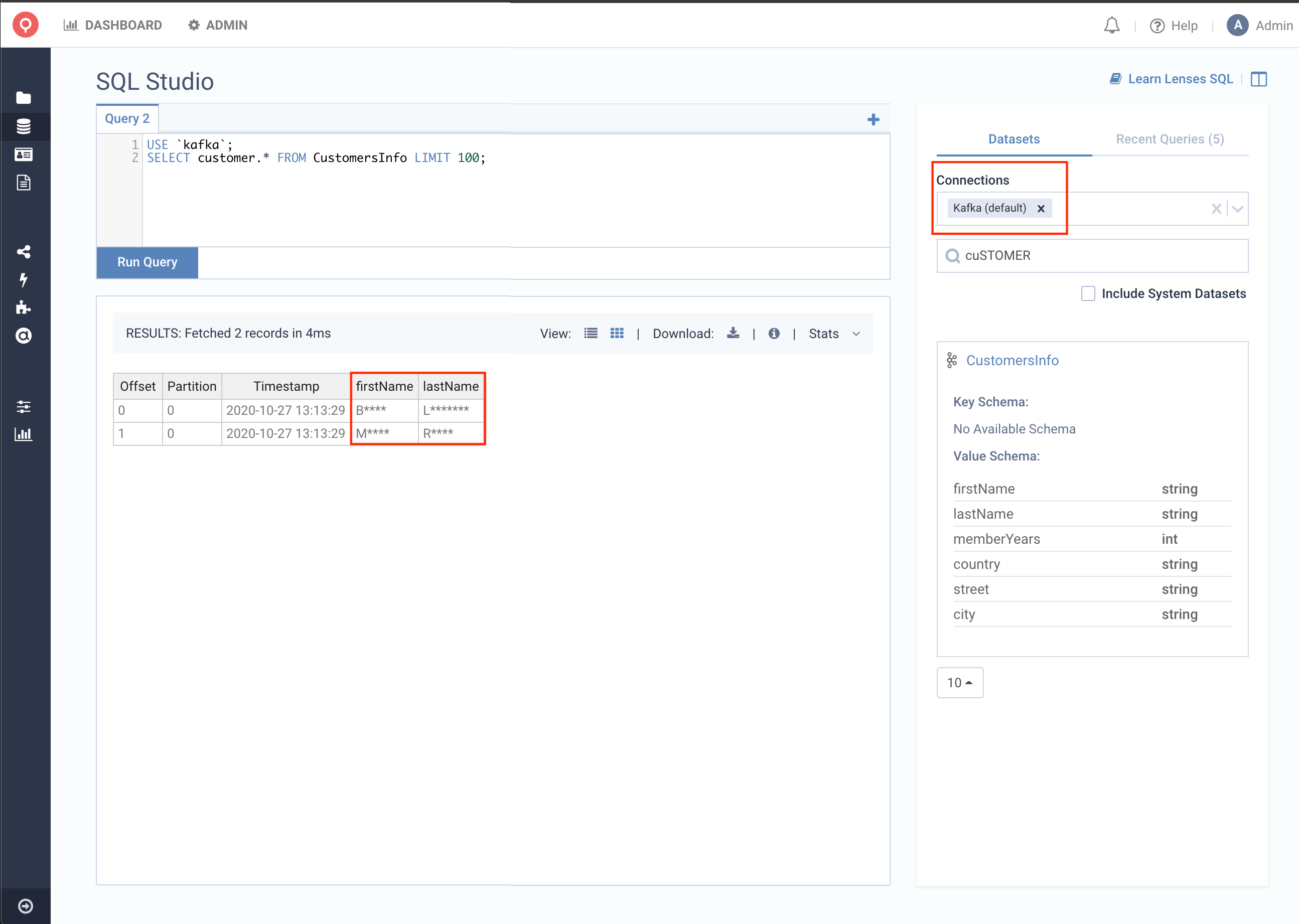
Once the Policy Full Name is created, any data on Kafka or ES, whether serialized as Avro, JSON, XML and Protobuf that
contains “firstName” or “lastName” will automatically be detected.
Apart from identifying all the sensitive data at a field level, Lenses will also protect the data for you. That means that anyone accessing data via Lenses (UI/CLI/API/SQL) can access production data while respecting the underlying data’s sensitivity.
In the image below, you can see that the fields firstName and lastName are obfuscated, and the First-1 policy is applied, just like
we wanted.
View Policy Details
We can now view the details of the Policy. By clicking the link in the Listing, you will be redirected to the Details Page.
There you will be able to see all the available information about the given policy. From Details, Applied Data and Detected Flows,
to quickly identify if an Application (SQL Processors, Kafka Connector, or Custom App) uses protected data.
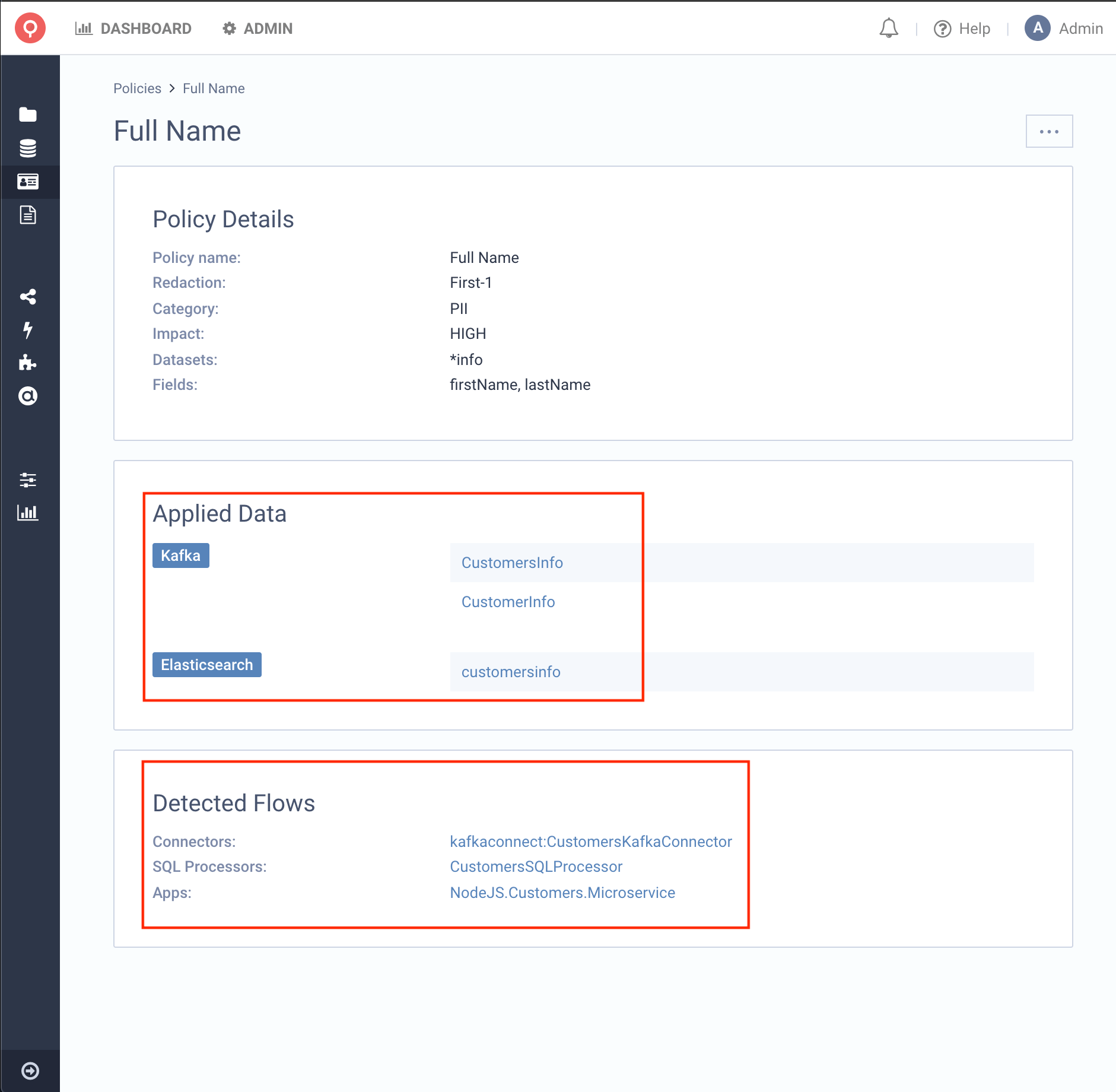
This example shows the Policy we just created and that it affects 2 Kafka Topics and 1 Elasticsearch Index. You can see that all Datasets end with the word info, exactly what we wanted to achieve.
We can also see that we have detected some Data Flows producing/consuming from those Datasets. In our case,
we see that we have 3 Applications that are consuming from CustomersInfo:
- An SQL Processor
- An Elasticsearch Sink Connector
- An External Microservice NodeJS Application
Edit & Delete Policy
You can, of course, Edit and Delete a Data Policy by clicking the ... button at the top right of the screen. You can also Delete a Policy by the Listing Page as well.
Data Policies on Explore
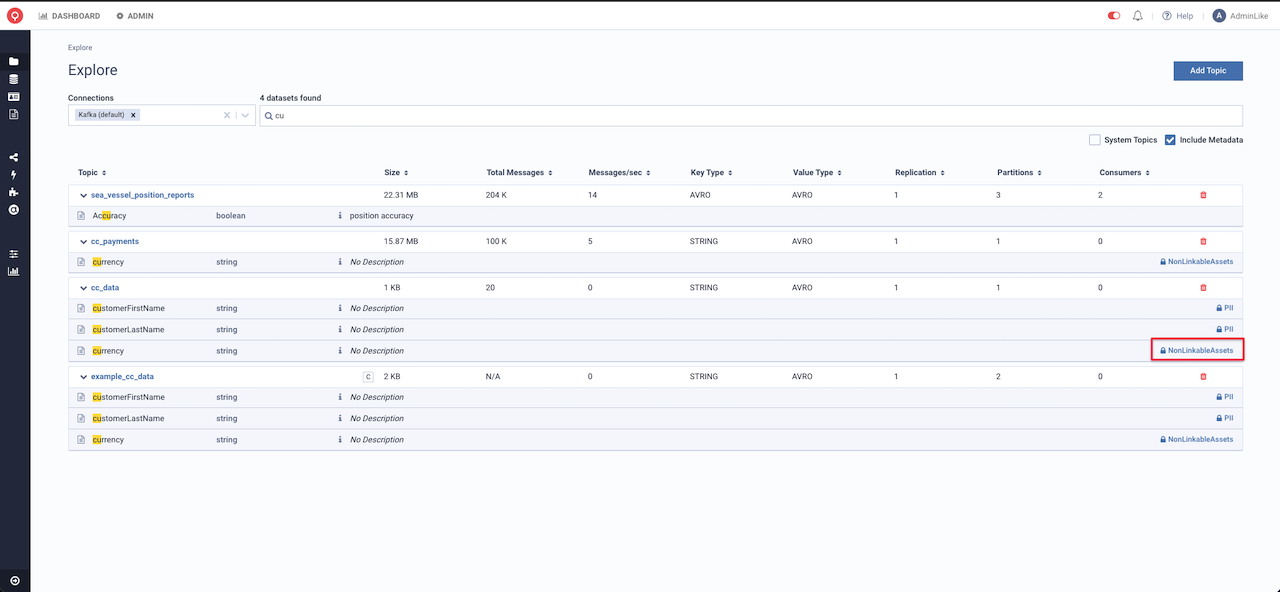
Lenses Data catalog is Data Policies aware. Obfuscated fields are now highlighted together with their respected Policies Categories
Below you can see, that when we are searching for cu, we can see that the search API, is returning all the fields containing cu like customerFirstName, currency which are protected
with Data Policies. On the other hand, the field accuracy is not.